¶ 应用介绍
- Deepseek 是由国产大模型公司深度求索研发。深度求索是量化巨头幻方量化旗下的科技公司。2025年1月20日,该公司正式发布推理大模型DeepSeek-R1。
- Deepseek-R1 作为一款开源模型,在数学、代码、自然语言推理等任务上的性能可以比肩OpenAI o1模型正式版,并且采用MIT许可协议,支持免费商用、任意修改和衍生开发等。
- DeepSeek-R1在后训练阶段大规模使用了强化学习技术,在仅有极少标注数据的情况下,极大提升了模型推理能力。此外,DeepSeek不仅将R1训练技术全部公开,还蒸馏了6个小模型向社区开源,允许用户借此训练其他模型。
- DeepSeek的论文显示,不同于过去AI模型往往依赖于监督微调(SFT,指AI模型通过已标注的数据进行训练),R1完全由强化学习驱动,证明了直接强化学习是可行的。
¶ 使用指南
- 平台提供了多种Deepseek的使用方式,包括命令行交互、webui交互、api调用等。
- 平台提供了Deepseek-R1的671B、70B、32B及以下参数量版本,用户可以直接使用。
- 为了让师生们更好地使用平台,我们推荐以下配置,其中8卡资源需要向管理员单独申请后开通:
| 模型参数规模 | CPU核数 | 内存数 | |
32B及以下 |
|||
70B |
|||
671B |
¶ 方法一:GPU集群 + SSH端口转发(推荐)
¶ 1.申请GPU节点
用salloc方式申请GPU集群的g078t2分区的A800节点或g125t分区的V100节点
2张V100卡可以运行70B及以下的模型
#例如指定g078t2分区,申请8张A800卡、64个cpu核心,使用项目账户扣费
salloc -p g078t2 -N1 --gres=gpu:8 -n 64 --comment=your_project_name
¶ 2.启动ollama服务
申请好计算资源后,先ssh连接到GPU计算节点。设置相应环境变量,并启动 ollama 服务。
export OLLAMA_TIMEOUT=36000
export OLLAMA_HOST=0.0.0.0:11434
export OLLAMA_MODELS="/opt/app/ollama/0.5.7/models"
export PATH=$PATH:/opt/app/ollama/0.5.7/bin
ollama serve
¶ 3.利用Chatbox调用API
¶ 3.1 建立ssh端口转发
在个人笔记本电脑的命令行执行以下命令,其中:65432是笔记本电脑的端口,gpu7是申请到的计算节点,11434是ollama服务在计算节点gpu7上监听的端口,u2010xxxx是您的超算平台账号,22854是访问GPU集群的端口号。
ssh -L 65432:gpu7:11434 u2010xxxx@10.160.16.3 -p 22854
输入账号对应的密码后,进入超算平台的workstation,不要关闭。此时,gpu7节点上的ollama服务可以在个人笔记本电脑通过这个API调用 http://127.0.0.1:65432 。
为避免端口冲突,可以在执行命令前查找一下端口是否被占用,例如:Windows执行 netstat -na|findstr 65432,Linux/MacOS执行 netstat -na|grep 65432
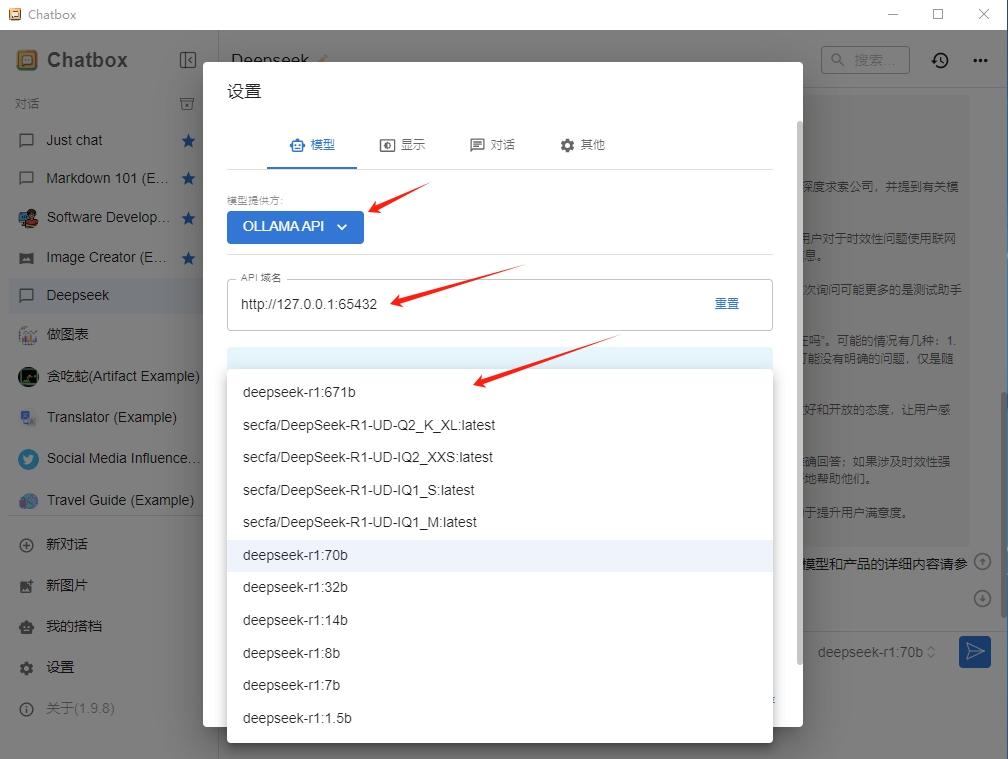
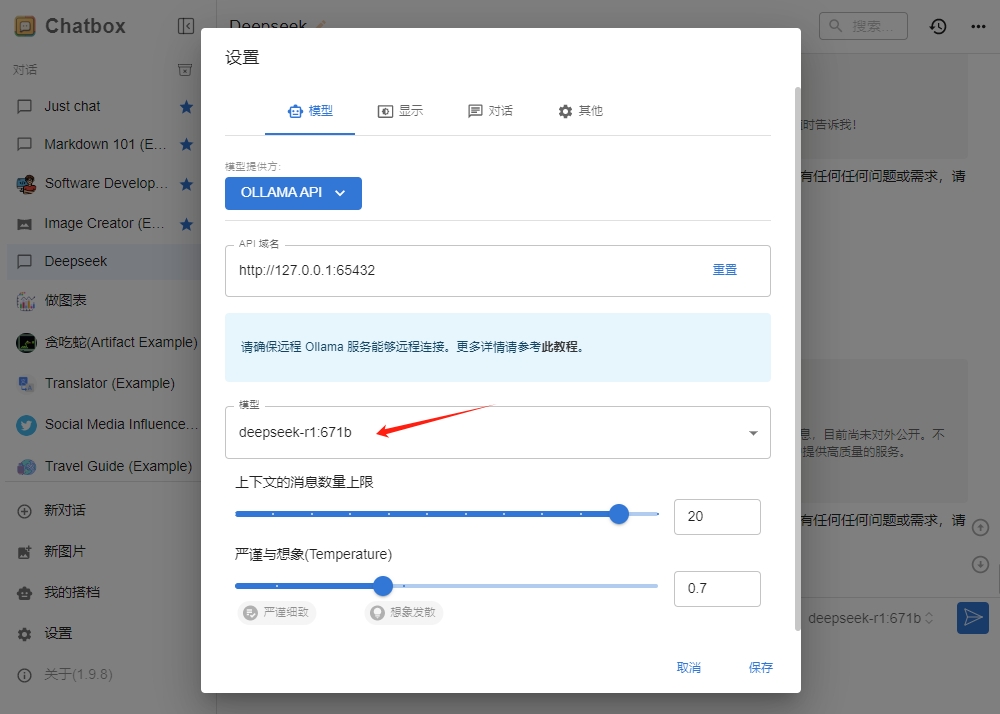
¶ 3.2 设置ollama API
在个人笔记本电脑上打开Chatbox软件,“模型提供方”选择“OLLAMA API”,“API域名”填写3.1步的http://127.0.0.1:65432,选择相应模型,保存。
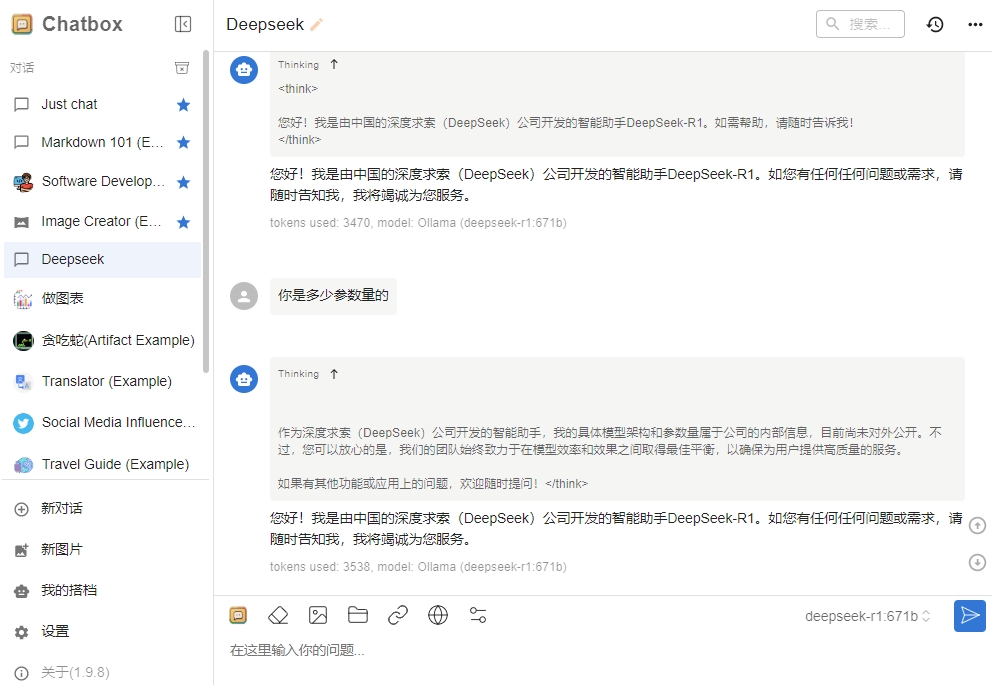
¶ 3.3 验证API可用
在Chatbox软件的对话框输入文字,验证API可用。
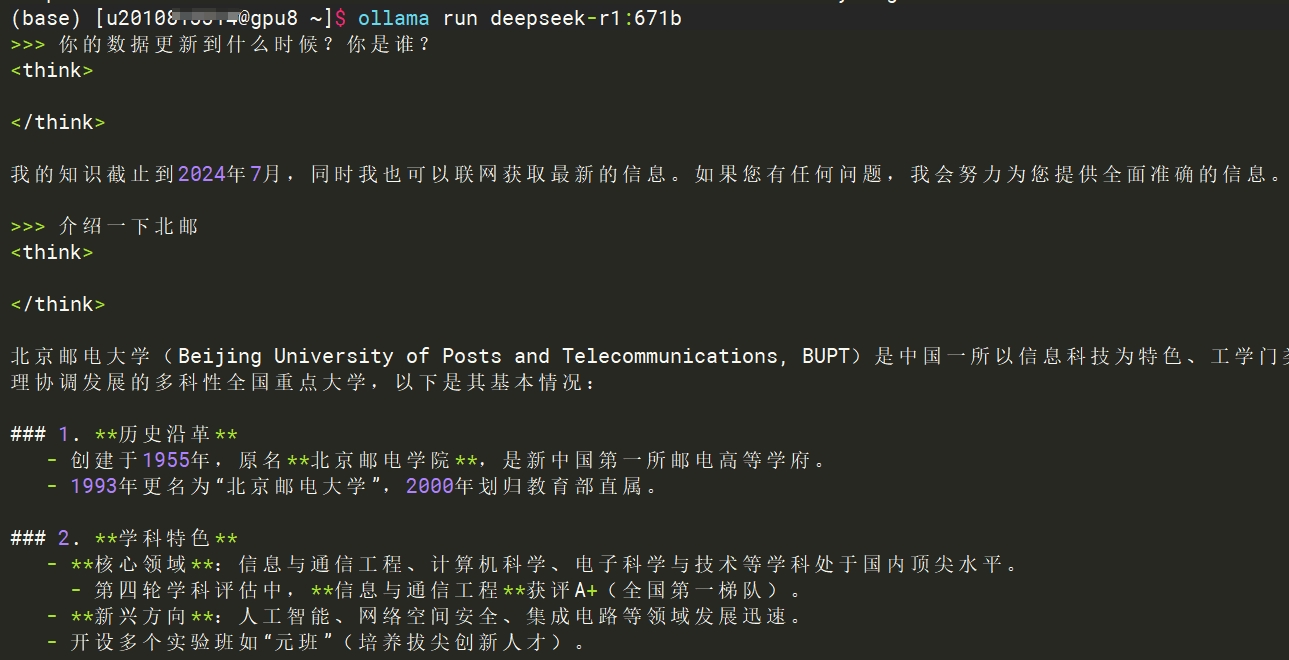
¶ 【可选】4.命令行加载DeepSeek模型并对话
如果想只体验与DeepSeek对话,可以打开一个新的ssh窗口,ssh连接到GPU计算节点,并在计算节点上运行下面的命令。
export PATH=$PATH:/opt/app/ollama/0.5.7/bin
ollama run deepseek-r1:671b
用户可以通过 ollama list 命令查看当前环境有哪些模型。
这样可以在命令行内开始对话
¶ 方法二:容器实例 + Chatbox
开始操作前请先到Chatbox官方网站下载Chatbox软件,并安装到个人电脑
¶ 1. 申请资源
在“GPU容器资源池1”创建DeepSeek容器实例。
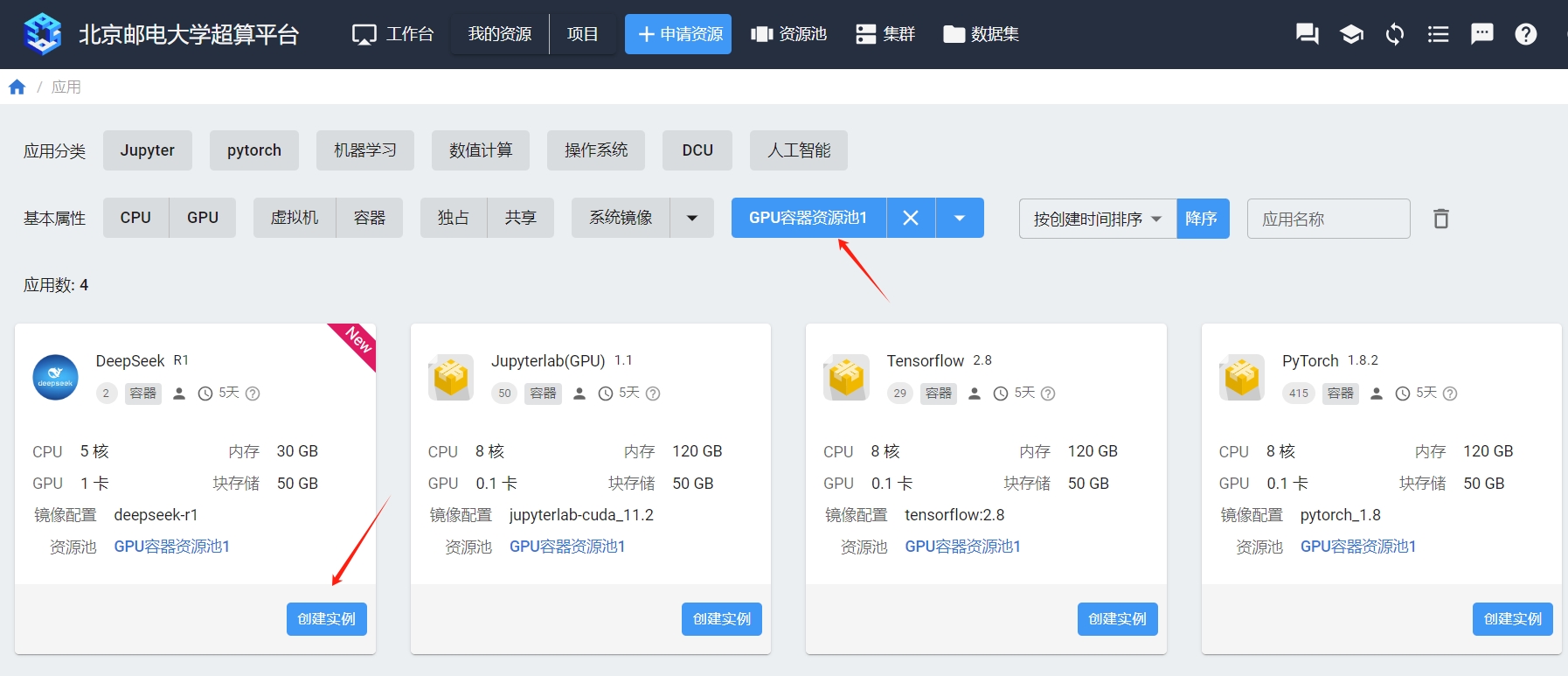
¶ 2. 获取API
在实例的详情页面,如图找到Ollama API的服务地址并复制。
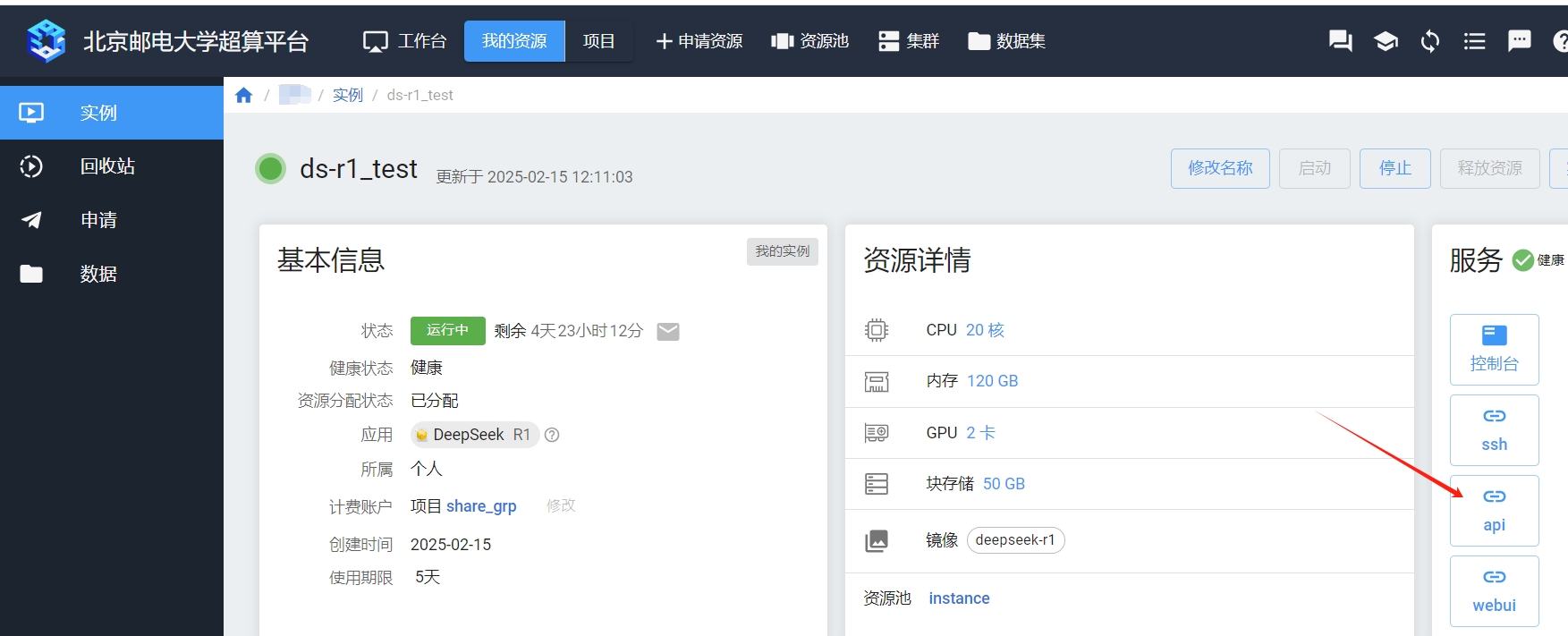
¶ 3. 配置Chatbox
在电脑上打开Chatbox软件,“模型提供方”选择“OLLAMA API”,“API域名”填写第2步复制的服务地址并加上http://前缀,例如:http://10.160.16.3:xxxxx,选择相应模型,保存。
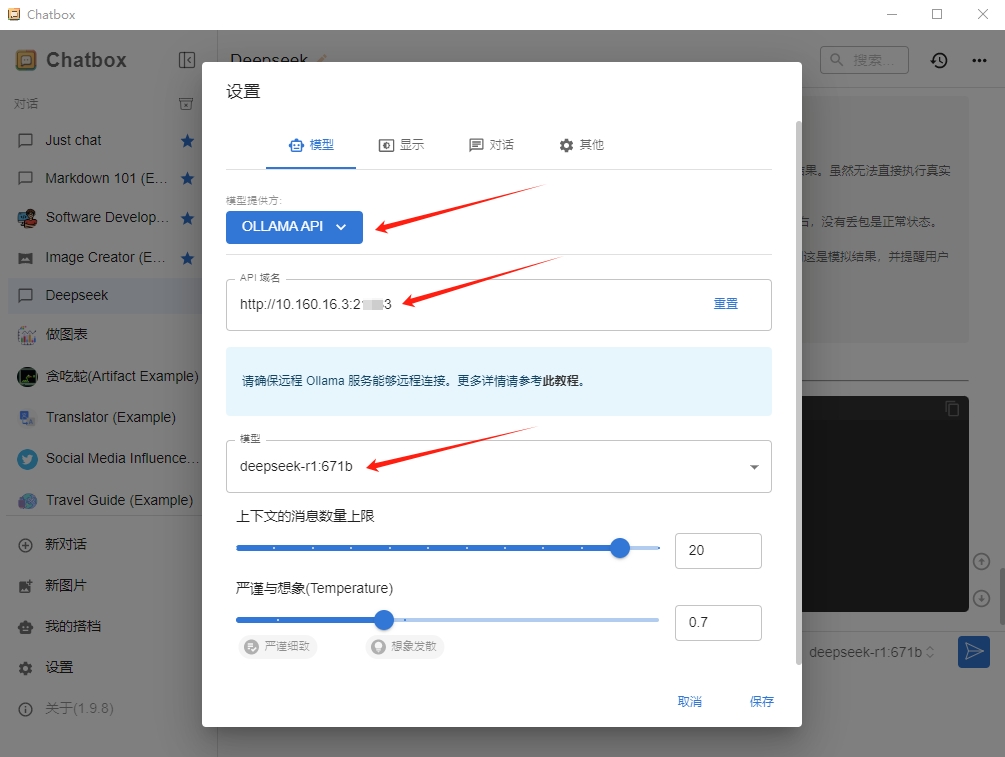
¶ 4. 开始对话
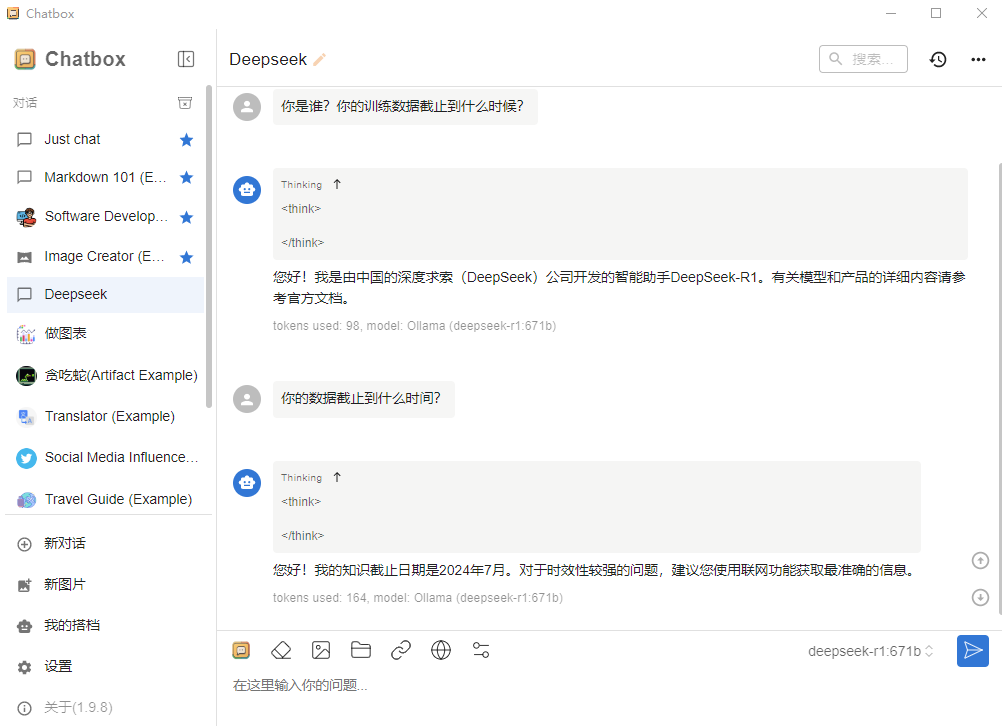
在Chatbox的对话框,输入您的文字。
Deepseek-R1的671B版本需要较长时间加载,请您耐心等待。
¶ 方法三:容器实例 + Page Assist
¶ 1.申请资源
在“GPU容器资源池1”创建DeepSeek容器实例。
¶ 2.安装插件
使用谷歌或火狐浏览器安装Page Assist插件,添加至扩展程序。
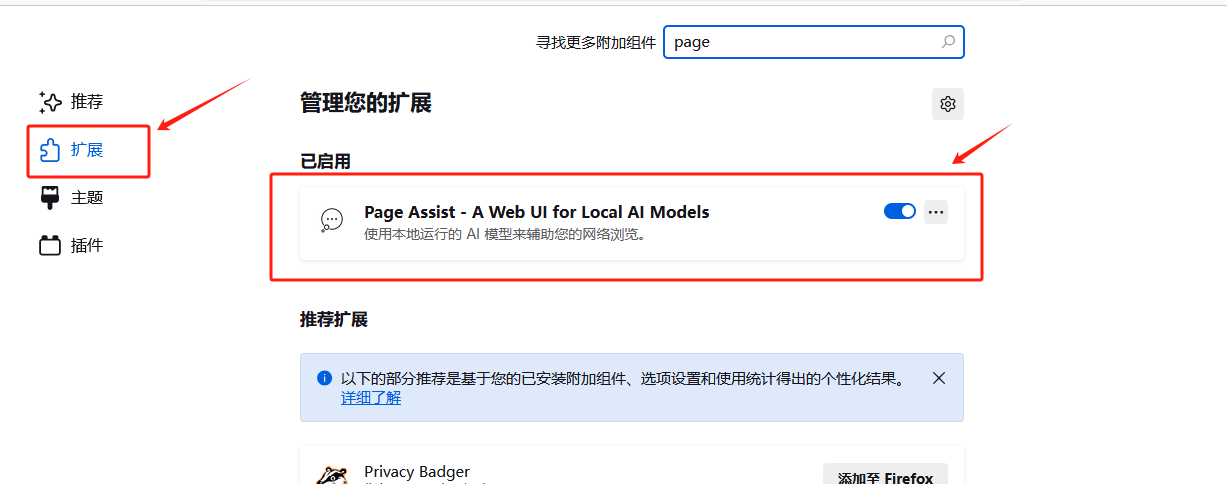
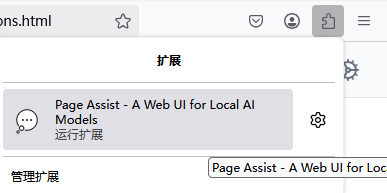
¶ 3.运行程序
运行扩展程序
¶ 4.配置设置
一般设置和Ollama设置,配置联网搜索引擎和Ollama API服务地址。


¶ 5.开始对话
在对话框内输入您的文字。
