¶ 公共集群
¶ 应用介绍
公共集群适合对Linux命令行和作业调度系统比较熟悉的用户。
对于刚刚开始学习使用集群的用户,推荐先了解Linux基本操作和Conda入门指南。
超算平台的公共集群采用SLURM作业调度系统,请了解Slurm作业系统 常用命令 。
¶ 集群分类
北邮超算平台一共有三个公共集群:GPU集群、CPU集群和NPU集群。
一、 GPU集群包括1个分区:g078t 、g125t以及dcu、mlu。
g078t分区允许任务运行的最长时间为7天。
- g078t分区的单个节点的双精度浮点算力是78TFLOPS,单节点8卡,单卡80G显存,共有18个节点。
g125t分区的单个节点的双精度浮点算力是125TFLOPS,单节点16卡,单卡32G显存,共有2个节点。dcu和mlu暂时用于国产化测试。
二、 CPU集群包括2个分区:c003t、b006t。
c003t分区允许任务运行的最长时间为7天。
- c003t分区的单个节点的双精度浮点算力是3TFLOPS,单节点40核心,单核心2.4GHz,共有60个节点。
- b006t分区的单个节点的双精度浮点算力是6TFLOPS,单节点96核心,单核心2.1GHz,共有1个节点。
三、 NPU集群包括1种分区:ascend。
- ascend暂时用于国产化测试。
¶ 登录节点和计算节点
公共集群中通常包含一个登录节点(workstation)、一个头节点(head)和多个计算节点(gpuN或cpuN)。
[username@workstation ~]$ cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.0.1 workstation workstation.example.com
192.168.0.2 head head.example.com
192.168.0.3 gpu1 gpu1.example.com
192.168.0.4 gpu2 gpu2.example.com
192.168.0.5 gpu3 gpu3.example.com
登录节点未配置GPU资源,仅供用户登录提交作业使用,故运行
nvidia-smi时无回显,即无法调用GPU资源。
在登录节点直接调用GPU资源,会产生如下所示的报错信息:
[username@workstation ~]$ nvidia-smi
-bash: nvidia-smi: command not found
用户需要在登录节点上申请资源后方可使用GPU计算节点,申请方式有两种,即通过sbatch提交作业的方式或使用salloc交互运行作业。
¶ 从登录节点sbatch批量式调用GPU资源
sbatch 主要用于向 Slurm 调度器提交批量作业,用户可以通过这个命令告诉调度系统要在计算节点上运行一个任务比如nvidia-smi,并且可以指定该任务所需的资源(如 CPU 数量、内存大小、运行时间等),调度器会根据集群的资源使用情况和用户请求的资源,将任务安排到合适的计算节点上运行。通过编写sbatch脚本,用户可以从登录节点批量的程序化的调用GPU资源,不需要登录到计算节点上。
sbatch脚本示例如下:
#! /bin/bash
### 表示这是一个bash脚本
#SBATCH --job-name=JOBNAME
### 设置该作业的作业名
#SBATCH --nodes=2
### 指定该作业需要2个节点数
#SBATCH --ntasks-per-node=40
### 每个节点所运行的进程数为40
#SBATCH --time=2:00:00
### 作业最大的运行时间,超过时间后作业资源会被SLURM回收
#SBATCH --comment project_name
### 指定从哪个项目扣费。如果没有这条参数,则从个人账户扣费
source ~/.bashrc
### 初始化环境变量
nvidia-smi
### 程序的执行命令
¶ 从计算节点salloc交互式调用GPU资源
公共集群的计算节点默认不允许用户直接登录,对需要交互式处理的任务,用户需要在集群的登录节点上,使用salloc命令申请该任务所需的资源(如 CPU 数量、内存大小、运行时间等),然后再ssh到分配的计算节点上进行交互式处理。salloc通常用于调试或者交互式处理。
使用后,请确保运行完作业后退出资源,否则计费系统将继续计费。
首先通过管理节点申请资源,以下示例为申请一个GPU计算节点,2个CPU核、1块GPU卡,指定最大占用时间为1小时,指定付费项目组是xxxx。
[username@workstation ~]$ salloc -N 1 -n 2 --gres=gpu:1 -t 1:00:00 --comment=xxxx
salloc: Pending job allocation 3452 ###生成任务ID为3452
salloc: job 3452 queued and waiting for resources
salloc: job 3452 has been allocated resources
salloc: Granted job allocation 3452
salloc: Waiting for resource configuration
salloc: Nodes gpu1 are ready for job ###分配gpu1节点供任务使用
SSH登录到分配到的GPU计算节点上。
[username@workstation ~]$ ssh gpu1 ###登录gpu1节点
Warning: Permanently added 'gpu1,192.168.0.3' (ECDSA) to the list of known hosts.
Last login: Fri Dec 31 03:19:41 2021 from 192.168.0.1
运行nvidia-smi命令
[username@gpu1 ~]$ nvidia-smi ###运行GPU指令
Fri Dec 31 03:57:17 2021
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 418.87.01 Driver Version: 418.87.01 CUDA Version: 10.1 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
===============================+======================+======================|
| 0 Tesla V100-PCIE... Off | 00000000:41:00.0 Off | 0 |
| N/A 25C P0 22W / 250W | 0MiB / 32480MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
计算完成后,使用两次exit命令退出。
要输入
exit两次,第一次exit是从计算节点退出到登录节点,第二次exit是释放所申请的资源。
[usernameo@gpu1 ~]$ exit ###运行完成后退出gpu1节点
logout
Connection to gpu1 closed.
[usernameo@gpu1 ~]$ exit ###释放所申请的资源
exit
salloc: Relinquishing job allocation 3452.
作业的默认优先级是100,如果您提交的作业占用节点数较多且不紧急,建议在脚本中加入友好值(--nice=XX),nice取值可以是1~99,此时作业的实际优先级=默认优先级-友好值=100-XX,允许其他消耗节点数较小的作业先于自己的作业运行,减少集群资源闲置时间。
¶ 环境变量
在高性能计算中,控制程序运行有两个主要的环境变量:PATH和LD_LIBRARY_PATH。其中PATH是系统默认查找可执行文件的路径,在PATH变量路径中的可执行程序可以通过直接输入程序名称来启动,而不在PATH变量中的程序需要输入可执行文件的完整路径才能执行。LD_LIBRARY_PATH控制的是程序在运行过程中需要用到的动态链接库的搜索路径,如果程序所依赖的动态链接库无法在系统的默认搜索路径以及LD_LIBRARY_PATH中找到,可执行程序会无法执行。
PATH和LD_LIBRARY_PATH里面存放的是以冒号分割的多个路径组成的字符串,当同一个可执行程序或动态链接库在不同的路径下同时存在时,在这两个变量里前面出现的路径具有更高的优先级,会优先被找到。
这两个变量简单的控制可以通过export PATH=或者export LD_LIBRARY_PATH=的方式进行设置。
系统中安装了MODULE工具以支持环境变量的复杂管理,具体内容可参考:https://modules.readthedocs.io/en/latest/
¶ 安装路径
超算平台上预先安装了常用的科学计算类的软件,默认安装路径为/opt/app/,用户可直接使用预编译好的可执行文件进行计算。
¶ 使用指南
请参见集群登录和帮助文档左侧->应用服务->集群工具。
¶ 常见问题
¶ 1. 如何在集群中使用个人目录和项目中的数据?
¶ home目录路径
/home/<username> #集群home目录
/users/<username> #个人home目录
/groups/<project_id>/home/<username> #项目home目录,注意id前加"g"
以用户 demo123
为例,该用户为某项目组成员,该项目组的id为700008,则对应的各个home目录为:
/home/demo123 #集群home目录
/users/demo123 #个人home目录
/groups/g700008/home/demo123 #项目home目录,注意id前加"g"
¶ 详细说明
公共集群进入后,默认是进入集群的home目录 /home/<username>,WEB页面对应的是“工作台”-“数据总览”-“public_cluster”的数据。
公共集群home目录内,只有当前用户有读写权限,集群其他用户无法访问。
公共集群home目录下的 share 目录是集群共享目录,集群中所有用户都可以读写。如果是希望共享的数据,需要放在 share 目录下。
下面以用户 demo123 为例,其中 a.txt 只有当前用户有访问权限, share 目录下的文件所有集群用户都能访问。
[demo123@workstation ~]$ cd ~
[demo123@workstation ~]$ pwd
/home/demo123
[demo123@workstation ~]$ ls
a.txt share
如果希望在集群中使用个人home目录中的数据,路径为 /users/<username>。集群中的个人home目录只有本人可以访问。
[demo123@workstation ~]$ cd /users/demo123
如果希望在集群中使用项目目录中的数据,路径为 /groups/<project_id>/home/<username> 。项目目录数据的访问权限请参见project 。
项目ID在项目基本信息中查询。
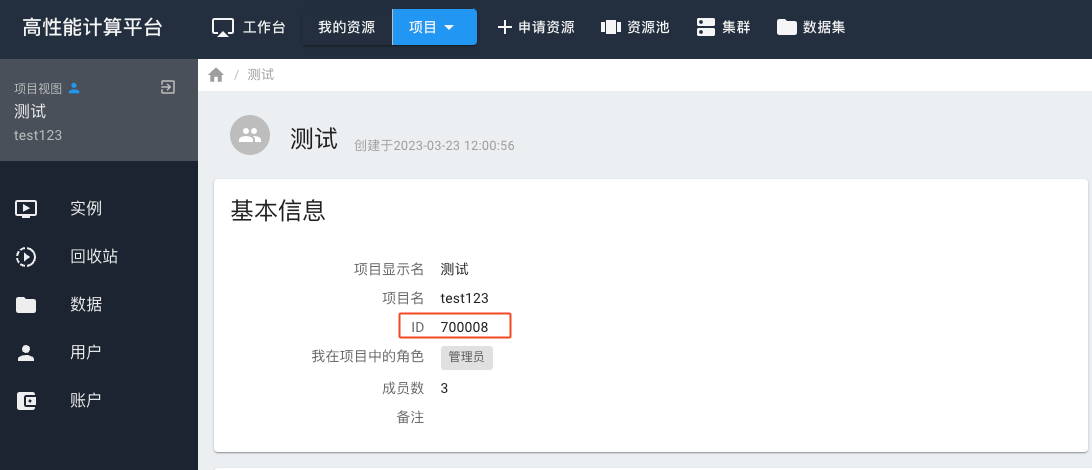
以上图为例,“测试”项目的id为700008,那么该项目下的数据路径为 /groups/g700008/home/demo123。
路径中,项目id前必须加上 g ,比如id为
700008,则路径中需改为g700008。